Abstract
Predictive maintenance (PdM) is a policy applying data and analytics to predict when one of the components in a real system has been destroyed, and some anomalies appear so that maintenance can be performed before a breakdown takes place. Using cutting-edge technologies like data analytics and artificial intelligence (AI) enhances the performance and accuracy of predictive maintenance systems and increases their autonomy and adaptability in complex and dynamic working environments. This paper reviews the recent developments in AI-based PdM, focusing on key components, trustworthiness, and future trends. The state-of-the-art (SOTA) techniques, challenges, and opportunities associated with AI-based PdM are first analyzed. The integration of AI technologies into PdM in real-world applications, the human–robot interaction, the ethical issues emerging from using AI, and the testing and validation abilities of the developed policies are later discussed. This study exhibits the potential working areas for future research, such as digital twin, metaverse, generative AI, collaborative robots (cobots), blockchain technology, trustworthy AI, and Industrial Internet of Things (IIoT), utilizing a comprehensive survey of the current SOTA techniques, opportunities, and challenges allied with AI-based PdM.
1. Introduction
The maintenance of the systems has recently become increasingly important for enhancing product efficiency and continuity. Different varieties of system maintenance exist, such as reactive, planned, proactive, and predictive [1]. Figure 1 summarizes them. Reactive maintenance only solves the issue when the system breaks down or malfunctions. The malfunction becomes apparent, and then the repairing steps are applied. Planned maintenance is previously scheduled to perform regular inspections and maintenance tasks at predetermined intervals to prolong the system’s life and reduce repair costs, regardless of whether the system has shown failure signs. Predictive maintenance (PdM) is an approach applying advanced analytics on the obtained data from multiple sensors to predict when the system tends to fail and organize the maintenance tasks accordingly to optimize maintenance intervals, reduce malfunction time, and enhance the system’s reliability.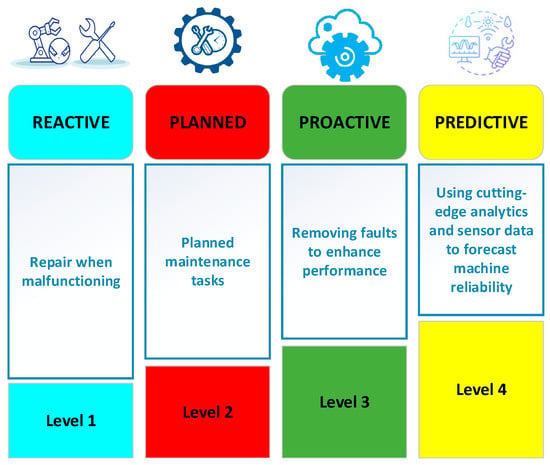
PdM has shown significant growth and advancements. Most recently, low-cost sensors have been developed, and new real-time condition monitoring systems have been successfully used to obtain big data. These developments, expert algorithms, and expert human experience brought considerable developments and progress in predictive maintenance. Current efforts are given to developing new multivariate statistical models and expert algorithms to improve predictions’ accuracy and reduce labor costs [1,2,3,4,5,6,7,8,9,10,11]. Reaching next-step autonomy in a robotics system is possible thanks to sophisticated artificial intelligence (AI)-based algorithms, models, and expertise. Moreover, the potential AI-based PdM reduces costs and boosts efficiency and safety. Hence, the researchers pay special attention to AI models and techniques to improve the autonomy and adaptability of robotic systems in complex and dynamic industrial environments [12,13,14,15,16,17,18,19,20,21,22].
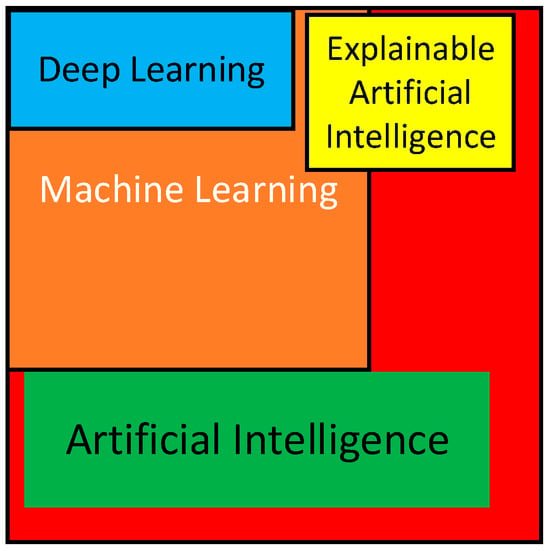
AI has been successfully employed in the automotive, manufacturing, energy, aerospace, and transportation industries by making real-time predictions and estimations of malfunctions and anomalies on big datasets [23]. It has been demonstrated that AI-based techniques, including machine learning and deep learning, exhibit improved performance and accuracy at PdM utilizing remaining useful life (RUL), fault diagnosis, and predictive maintenance scheduling [23,24,25,26,27,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42,43]. Using AI brings some challenges, such as transparency, explainability, system integration, and ethical issues [44], leading to explainable artificial intelligence (XAI) [45]. Figure 2 shows the general AI cover. This paper aims to comprehensively survey the current state-of-the-art techniques, challenges, and opportunities exhibited by AI-based PdM, focusing on key components, trustworthiness, and future trends. The most recent outcomes and innovations in the field are discussed in this paper by suggesting directions for further investigation. Finally, it gives some insights into the most recent research and advancements in the subject and assists in suggesting prospective areas for future research by providing a thorough overview of the existing literature.
Research Questions
This study examines current advances in AI-based PdM, particularly emphasizing next-generation autonomy. The following research inquiries are what this review is based on:
-
What are the main components of AI-based PdM systems?
-
What are the state-of-the-art (SOTA) PdM methods? Regarding accuracy, cost-effectiveness, and scale, what are their advantages?
-
What are the advantages of AI-based PdM techniques over traditional techniques regarding performance and cost-effectiveness?
-
What are the challenges and limitations of AI-based PdM?
-
How can AI-based PdM systems ensure high transparency and explanation?
-
How can AI be integrated into existing PdM systems and workflows?
-
What are the ethical issues in AI-based PdM?
-
How can an efficient human–machine interaction in AI-based PdM systems be obtained?
-
How can testing and validation of AI-based PdM systems be effectively conducted in real-world scenarios?
-
What are recent advances and future trends in AI-based PdM?
Taking in the research questions, the contributions of this review are (i) the description of the main components of AI-based PdM systems, (ii) the analysis of the SOTA methods in PdM, (iii) comparison of the AI-based PdM with traditional approaches, (iv) investigation of the challenges and limitations of AI-based PdM, (v) assessment of transparency and explainability in AI-based PdM, (vi) integration of AI into existing PdM systems and workflows, (vii) investigation of ethical issues related to AI-based PdM, (viii) enhancing human–machine interaction in the AI-based PdM systems, (ix) effective testing and validation of AI-based PdM systems, and (x) study of the AI-based PdM advances and emerging topics.
The rest of the paper is organized as follows: Section 2 comprehensively describes the key components of AI-based PdM. The SOTA for PdM and its enabling technologies are presented in Section 3. Then, Section 4 focuses on transparency and explainability in AI-based PdM. The challenges and limitations of using AI for PdM autonomy are highlighted in Section 5. Section 6 presents recent advances and future trends in AI-based PdM. Conclusions are given in Section 7.
2. Key Components in AI-Based Predictive Maintenance
AI-based PdM can be fundamentally broken down into six distinct components: data preprocessing, AI algorithms, decision-making modules, communication and integration, and user interface and reporting, as shown in Figure 3. This section briefly discusses each component to understand how they work together to enable AI-based PdM.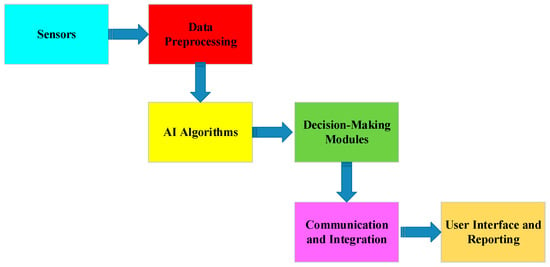
-
Sensors: Sensors are the frontline data collectors in a PdM system. These specialized devices are strategically placed on equipment and machinery to continuously monitor various parameters, such as temperature, pressure, vibration, and more. Sensor data provides real-time insights into equipment health and forms the foundation for predictive maintenance analysis.
-
Data Preprocessing: Raw data obtained from sensors often contains noise and inconsistencies. Data preprocessing is the initial step in preparing the data for analysis. It includes data cleaning, normalization, and missing data handling. High-quality data are essential for accurate PdM modeling.
-
AI Algorithms: AI algorithms, including machine learning and deep learning techniques, are the brain of the PdM systems. The algorithms analyze the data to identify the most important features relating to possible failures. They learn from historical data to predict equipment failures, anomalies, and RUL.
-
Decision-Making Modules: The insights and predictions generated by the AI algorithms are processed by decision-making modules. These modules are responsible for determining when maintenance actions are needed. They can recommend preventive or corrective maintenance tasks, schedule maintenance, and trigger alerts to maintenance teams when necessary.
-
Communication and Integration: Communication and integration ensure that the insights generated by the system are effectively translated into action. This component involves interactions with various stakeholders, including maintenance personnel and management. Furthermore, integration with enterprise systems such as ERP and asset management software aligns predictive maintenance with broader organizational goals.
-
User Interface and Reporting: To make these insights accessible to maintenance staff and decision makers, user interfaces and reporting tools are essential. The tools make it easier for users to understand complex data patterns and make informed decisions by providing data visualization, dashboard, and reporting capabilities. Data visualization tools and dashboards communicate data insights and forecast information to maintenance teams and decision makers. Visual aids help understand complex data patterns and make informed decisions.
The following three data-related units are added to the advanced AI methods to obtain resilient, reliable, secure, and highly stable results using AI-based PdM in complex and dynamic environments.
Sensor data and the Internet of Things (IoT) integration: Integrating IoT and sensor technology is pivotal in next-step autonomy for PdM tasks. The IoT sensors are strategically placed in equipment and machines to monitor their condition in real-time continuously.
Data integration: Data integration combines data from various sources, including historical maintenance records, real-time sensor data, external factors (e.g., weather), and production schedules. This holistic view of equipment health enhances decision making.
Digital twins: Digital twins create virtual replicas of physical assets, facilitating real-time simulation and monitoring. AI systems monitor these digital twins, identifying performance irregularities and recommending optimal maintenance strategies before any physical equipment is adversely affected.
Edge and cloud computing: Edge computing proceeds closer to the data source through IoT sensors for real-time analysis rather than in a centralized data center, which reduces latency and enables real-time analysis. Cloud computing stores and manages enormous amounts of data to analyze historical events.
The transport equipment category in Table 3 is noted as an essential field with six studies. The other machinery and equipment category is also notable with five works. On the other hand, the categories computers and communication equipment, industrial machinery and equipment, and buildings and other structures have a lower level of interest, with one study each, respectively. As a result, industries such as electrical equipment, machinery, electronic and optical equipment, and fabricated metal products are popular areas for AI and maintenance. On the other hand, computers and communication equipment, industrial machinery and equipment, and buildings and other structures categories have received more limited attention. These results are essential guidance for directing future research and development efforts.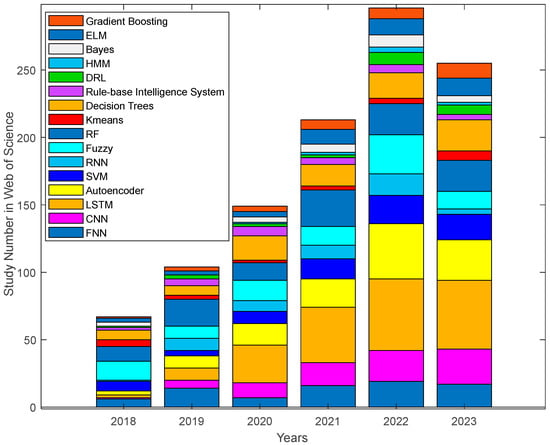
On the other hand, manufacturing industries, including automotive, aircraft, semiconductor, machine tools, gearbox, pharmaceutical, electronics, steel, robotics, industrial robotics, air conditioning, and industrial robots, are the industry sectors receiving the most attention in AI and maintenance, with 22 studies. This wide-ranging industry shows a significant research focus as it includes a variety of subsectors.
The industries of ‘electrical and electronics’ and ‘electronics’ also have attracted attention with 13 studies. Technological advances and maintenance practices have been reflecting significant interest in this industry. The transport, automotive, high-speed railway, autonomous vehicles, railways, and rail transport industries represent an important research area with ten studies. The combination of subsectors such as automotive, high-speed rail, and autonomous vehicles shows a wide range of topics covering various aspects of this industry. The industries of ‘metals and plastics’ and ‘metal and metallurgy’ have five studies. The energy and sustainability, nuclear power, nuclear energy, renewable energy, and wind energy industry is also a prominent field with five studies and covers a wide range of topics related to energy sustainability.
Information technology, cloud services and data centers, electric vehicle battery technology, medical, medical devices and healthcare services, large service management, building and construction, hydraulics, and architecture, engineering, construction, and facility management industries are important industries represented with two studies. A limited number of studies represent infrastructure, pumping systems, marine, textile, logistics and parcel delivery, steel strip processing, chemical industry, aviation, and home energy management.
In addition, Table 3 also shows different PdM tasks and study numbers. RUL, cost, and charge estimation tasks have attracted attention with 11 studies. These tasks cover strategically essential issues such as estimating the useful life of equipment and determining maintenance costs. Fault detection tasks are a vital topic, with 12 studies focusing on the early detection and prevention of malfunctions that may occur in systems. The condition and vibration monitoring task has attracted the attention of nine studies. The anomaly detection task is a distinct area with four studies focusing on detecting unexpected situations and abnormal behavior. Other tasks are represented by only one study each and seem to concentrate on more specific topics. These tasks include product lifecycle management, component fatigue strength prediction, PdM by a digital intelligent assistant, blockchain framework for PdM, and a big data analytics framework. As a result, basic tasks such as failure prediction, RUL estimation, fault detection, and anomaly detection are popular areas of AI and maintenance. In contrast, other tasks are more specialized and focus on specific topics.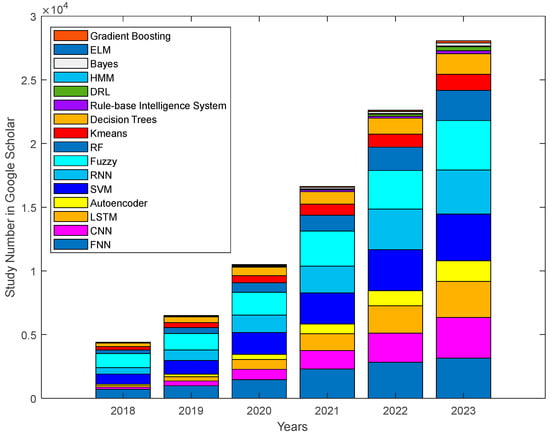
Although PdM tasks often appear to be primarily classification and regression problems in Table 3, the presence of unknown events and the general nature of the data with ambiguous labels clearly shows the importance of unsupervised learning, reinforcement learning, and statistical and probabilistic applications in PdM applications.
In addition, Table 2 includes some PdM tasks without using AI. Ref. [89] includes production quality prediction in the textile industry. Refs. [101,102,103] use thermal imaging technology in railways, medical, and hydraulics industries. Ref. [110] applies data management, predictive data analytic toolbox, recommender and decision support dashboard, and semantic-based learning and reasoning for PdM in the automotive manufacturing industry. Ref. [114] introduces the optimal maintenance strategy applying reliability analysis, sensitivity analysis, and a continuous stochastic process in the rail transport industry. Ref. [115] applies a discrete-event simulation framework for post-prognostic decisions in the aviation industry. Ref. [128] introduces a predictive analytics software platform in the manufacturing industry. Moreover, Ref. [91] includes quality management in the vinyl flooring industry using big data analytics and optimization and edge computing without having a PdM task, but it is related indirectly.
Figure 4 and Figure 5 show the number of studies carried out using different machine learning methods such as FNN, CNN, LSTM, autoencoder, SVM, RNN, fuzzy, RF, K-means, decision trees, rule-based intelligence system, DR, HMM, Bayes, ELM, and gradient boosting in Web of Science and Google Scholar for 2018 to 2023, respectively. Total study numbers in Web of Science and Google Scholar have been determined as (67, 104, 149, 213, 296, and 255) and (4406, 6506, 10,498, 16,638, 22,619, and 28,069) over 2018–2023, respectively. Both the results in Google Scholar and Web of Science clearly show that the fusion of PdM and AI will continue over the years. Since 2019, there has been a notable increase in the use of deep learning methods, specifically LSTM, CNN, and autoencoder, with a particularly pronounced surge in the utilization of DRL in the last two years. Additionally, SVM has maintained its relevance since 2018, and its usage has continued to grow. Another remarkable result has been observed in decision trees. The use of decision trees has shown a consistent upward trend since 2018. Notably, there has been a visible increase in the adoption of fuzzy and rule-based methods. Moreover, HMM, Bayes, gradient boosting, and FNN also exhibit a growing trend in usage since 2018. Even these escalating values in fundamental AI methods underscore the inevitability of AI becoming indispensable in future research endeavors. All the mentioned subjects show current relevance and an exponential increase has emerged, which signifies a robust and growing interest in these topics, indicating that AI will be indispensable in future studies. As a result, the figures exhibit an evolving landscape characterized by an increasing breadth of methods employed in PdM applications, suggesting a continuous effort by researchers to explore and integrate diverse machine learning methods, indicating the adaptability of the field and the ongoing quest for innovative approaches.
4. Transparency and Explainability in AI-Based Predictive Maintenance
Model interpretability is critical to AI, as it allows us to gain insights into complex models’ black-box nature and build trustworthy models. Various techniques have emerged to show how these models make predictions and decisions. Ref. [150] exhibited two concepts titled explainability and interpretability used in the XAI area. If the model’s design is understandable to a human being, it is considered interpretable. On the contrary, explainability ties into the idea that explanation is a form of interaction between humans and decision makers. Explainability is regarded as a post hoc tool because this specification covers the techniques used to transform an uninterpretable model into an explainable one.
On the other hand, ref. [151] mentioned that if the models are inherently interpretable, they have their own explanations, which align with the model’s calculation. This implies that interpretability inherently includes explainability. In the interpretable model, each step of the decision-making process can be traced. Still, there remains a gap in explaining why this specific sequence of steps was chosen during the decision-making process. Explainable models are interpretable by default, but the reverse is not always true [152], indicating that explainability is a subset of interpretability. In explainable AI systems, it can be challenging to understand how the model reached a decision, but it can grasp the underlying reasoning behind it. XAI takes a broader approach, striving to design inherently transparent and interpretable models for humans.
The interpretability techniques are classified in different ways. One way is to separate them into two branches, post hoc and ad hoc, concerning the training process [153]. Post hoc techniques use external tools to analyze the trained models. The techniques rely on input perturbations. That is why they can provide unreliable results in cases like adversarial attacks, as in [154].
Moreover, they are not concerned about the model’s inner dynamics and the actions to generate different features. Ad hoc techniques modify the model’s inner dynamics to facilitate understanding, and the model comes with some explanations during the training itself. The post hoc techniques require feature analysis, model inspection, saliency maps, proxy models, mathematical analysis, physical analysis, and explanation by using text and case to extract the explanations. They are divided into “model agnostic” and “model specific”. Model-agnostic models also use any model covering neural networks.
On the other hand, model-specific techniques are developed as specific to the model. Some examples of post hoc techniques are local interpretable model-agnostic explanations (LIME) [155] and SHapley Additive exPlanations (SHAP) [156], class activation map (CAM) [157], layer-wise relevance propagation (LRP) [158], and gradient-weighted class activation mapping (Grad-CAM) [159]. Ad hoc methods include approaches to explaining the model in an explicitly understandable manner, using hand-crafted criteria for the selection of features or incorporating heuristics based on current physics [160,161].
Ref. [162] also classified the interpretation techniques as local and global. Local interpretability provides single predictions, whereas global predicting provides interpretation to make new predictions from model features. Local methods such as LIME and SHAP provide model-agnostic means to explain and interpret the predictions generated by a wide range of machine-learning models. Deep learning models, known for their complexity, benefit from techniques like Grad-CAM and attention mechanisms, which offer insights into the input regions that influence their decisions.
Some approaches to achieving model interpretability include techniques such as partial dependence plots (PDP) [163], decision tree visualization [163,164], attention module [165], and feature importance calculation by using methods such as wrapper, filter, embedded, and dimension reduction techniques [166]. PDPs represent a method of showing the relationship among one or several components and the expected outcomes of machine learning models. They give us an insight into how changes affect model predictions for a given feature. The structure of the decision tree, the observed features split, and the way the tree makes decisions based on the input features are displayed in the decision tree visualization.
On the other hand, the attention module contains a mechanism for generating feature weights consisting of parallel hidden layers. Each module part provides a value between 0 and 1, which shall be multiplied by the suitable feature to enter the rest of the network. The module can be visualized. Feature importance helps understand the features with the most weight in the model’s predictions. Wrapper methods are trained with various input features to obtain the best results using heuristic and sequential search algorithms, which is time consuming [167]. Filter methods employ statistical metrics such as the Pearson correlation coefficient, mutual information, and X2 test prior to training to identify the importance of features. The techniques are unrelated to the model or its predictions after training, and they have no interest in interactions between features [168]. Embedded methods work on the subsets of the data along with techniques such as random forest, least absolute shrinkage and selection operator (LASSO) regression, ridge regression, regularization, decision tree, and XGBoost [169,170]. Dimension reduction techniques such as PCA, ICA (individual component analysis), linear discriminant analysis (LDA) reduce the dimensionality of the dataset to obtain a smaller set of principal components that explain most of the variance in the data [171].
In the literature, there are a lot of other methods, such as rule-based systems and sensitivity analysis. Rule-based systems utilize logical rules to describe the decision-making process of a model, making the decision logic explicit and understandable [172,173]. Lastly, sensitivity analysis helps identify the most influential input variables, contributing to a clearer understanding of a model’s predictive behavior. In an era where AI plays an increasingly prominent role, these interpretability techniques and methods are indispensable tools for building trust, improving model performance, and ensuring ethical and accountable AI systems.
Table 6 summarizes interpretable and explainable studies between 2018 and 2023 and their application content. In [174,175,176,177,178,179,180,181,182,183], SHAP, LIME, ELI5, integrated gradients, SmoothGrad, and LRP have been used. Refs. [184,185,186,187,188,189] use the semantic web rule language, rule-based expert systems, fuzzy systems, quantitative association rule mining (QARM), and data-driven sensitivity analysis. In [190,191,192,193,194,195,196,197,198,199,200,201,202,203,204], some techniques and visualizations such as decision trees, graph-based approaches, the attention modules used together with LSTM, generative adversarial networks (GAN), PDPs, and feature importance calculation methods. Refs. [205,206,207,208] give some new algorithms, including interpretability and explainability, such as temporal fusion separable convolutional network, federated learning, HMM, and reinforcement learning.