

Today, extending our series on the history of the LLM, we’d like to tell you the fascinating story of the “AI winter” – a period of reduced funding and interest in AI research. You’ll see alternating excitement and disappointment, but important research always persists. Join us as we explore the evolving nature of AI in this most comprehensive timeline of the AI winter. (If you don’t have time now, be sure to save this post for later! (It’s worth a read, and there are some worthwhile lessons in it).
Winter #1, 1966: Machine Translation
As discussed in the first edition of this series, NLP research originated in the early 1930s and began with work on machine translation (MT). However, after the publication of Warren Weaver’s influential memo in 1949, significant advances and applications began to appear.

The memo generated a great deal of excitement in the research community. Over the next few years, a number of noteworthy events occurred: IBM began development of the first machine, MIT appointed its first full professor of machine translation, and several conferences were held devoted to MT. This activity culminated with the public demonstration of the IBM-Georgetown machine, which attracted widespread attention in leading newspapers in 1954.

Another factor driving the field of mechanical translation is the interest shown by the Central Intelligence Agency (CIA). During this period, the CIA believed strongly in the importance of developing machine translation capabilities and supported such initiatives. They also recognized that the impact of the program went beyond the interests of the CIA and the intelligence community.

As with all AI booms followed by a desperate AI winter, the media tends to exaggerate the importance of these developments. Headlines about IBM’s Georgetown experiment proclaimed phrases such as “electronic brain translates Russian,” “bilingual machine,” “robot brain translates Russian into King’s English,” and “multilingual genius. “multilingual genius”. However, the actual demonstration involved translating a select group of just 49 Russian sentences into English, while the machine’s vocabulary was limited to 250 words. In the long run, the study found that humans need a vocabulary of about 8,000 to 9,000 word families to understand written text with 98 percent accuracy.

The demonstration caused quite a stir. However, there were others who were skeptical, such as Professor Norbert Wiener, who is considered one of the early pioneers in laying the theoretical foundations for the study of artificial intelligence. Even before Weaver’s memo was published, and certainly before the demonstrations, Wiener expressed his skepticism in a 1947 letter to Weaver, saying:
I am frankly afraid that the boundaries of words in different languages are too blurred, and the emotional and international connotations too wide, for any quasi-mechanical translation program to be promising. […] At this point in time, it seems premature to mechanize language beyond such a stage as designing photoelectric reading opportunities for the blind.
Skeptics appear to be in the minority, however, as the Dreamers masked their concerns and succeeded in obtaining the necessary funding. Five government agencies played a role in funding the research: the National Science Foundation (NSF) was a major contributor, along with the Central Intelligence Agency (CIA), the Army, the Navy, and the Air Force. By 1960, these organizations had collectively invested nearly $5 million in projects related to mechanical translation.
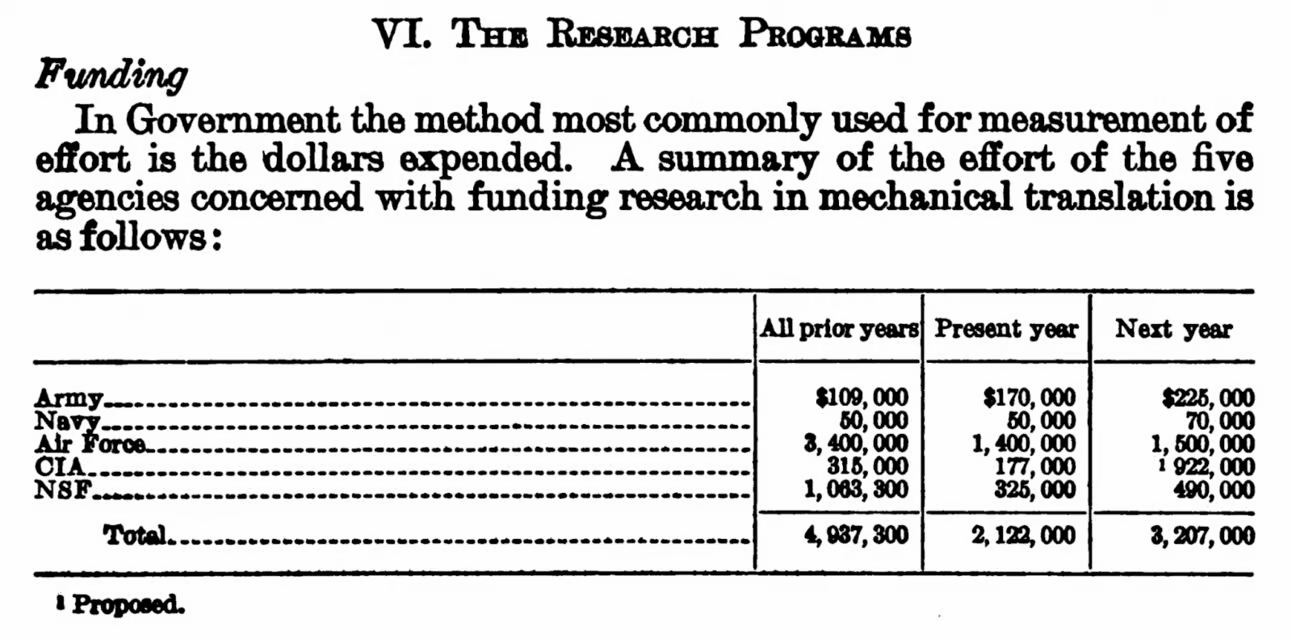
By 1954, mechanical translation research had generated enough interest to be recognized by the National Science Foundation (NSF), which awarded a grant to the Massachusetts Institute of Technology (MIT). Negotiations took place between the CIA and NSF, and the two directors corresponded in early 1956. NSF agreed to administer any desirable machine translation research program agreed upon by all parties involved. According to NSF testimony in 1960, eleven groups in the United States were involved in various aspects of federally supported machine translation research. The Air Force, the U.S. Army, and the U.S. Navy have also shown great interest.
Artificial Intelligence is born
The year after the public demonstration of the IBM-Georgetown machine, McCarthy coined the term “Artificial Intelligence” in his 1955 proposal for the Dartmouth Summer Meeting. This event sparked a new wave of dreams and hopes, further solidifying existing enthusiasm for the technology.
New research centers sprang up, equipped with enhanced computer power and greater memory capacity. At the same time, high-level programming languages were developed. These advances were made possible, in part, by significant investments by the Department of Defense, a major supporter of NLP research.
Advances in linguistics, particularly in the area of formal grammar models proposed by Chomsky, have inspired several translation projects. These developments seem to promise significant improvements in translation capabilities.
As John Hutchins writes in A Brief History of Machine Translation, there were many predictions of a coming “breakthrough”. However, researchers soon encountered “semantic barriers” that posed complex challenges without immediate solutions, leading to growing disillusionment.

The main blow came from the findings of the ALPAC panel, commissioned by the U.S. government and led by Dr. Leland Haworth, director of the National Science Foundation, which supported the basic ideas articulated. In their report, machine translations were compared with human translations of a variety of texts in the physical and earth sciences. Conclusion: In all the examples reviewed, machine translation output was less accurate, slower, more costly and less comprehensive than human translation.
In 1966, the National Research Council abruptly stopped all support for machine translation research in the United States. After the successful use of computers to decrypt German ciphers in the United Kingdom, scientists incorrectly assumed that translating written text between languages was no more challenging than decoding codes. However, the complexity of dealing with “natural language” proved to be far greater than expected. Attempts to automate dictionary lookups and apply grammatical rules produced absurd results. After twenty years and twenty million dollars, there was still no solution in sight, prompting the National Research Council to terminate the research effort.
Despite the lack of adequate theoretical foundations in linguistics, disillusionment arose because of high expectations for practical applications in the field. Researchers focused more on theoretical aspects than on practical implementation. In addition, the limited availability of hardware and the immaturity of technological solutions posed additional challenges.
