
Abstract
Active Learning has emerged as a viable solution for addressing the challenge of labeling extensive amounts of data in data-intensive applications such as computer vision and neural machine translation. The main objective of Active Learning is to automatically identify a subset of unlabeled data samples for annotation. This identification process is based on an acquisition function that assesses the value of each sample for model training. In the context of computer vision, image classification is a crucial task that typically requires a substantial training dataset. This research paper introduces innovative selection methods within the Active Learning framework, aiming to identify informative images from unlabeled datasets while minimizing the number of required training data. The proposed methods, namely Similari-ty-based Selection, Prediction Probability-based Selection, and Competence-based Active Learning, have been extensively evaluated through experiments conducted on popular datasets like Cifar10 and Cifar100. The experimental results demonstrate that the proposed methods outperform random selection and conventional selection techniques. The superior performance of the novel selection methods underscores their effectiveness in enhancing the Active Learning process for image classification tasks.
Introduction
Image classification technology has become pivotal across a range of sectors, including healthcare, public safety, and intelligent transportation. The development of a robust image classification model typically necessitates a substantial, well-labeled dataset. However, the availability of such datasets is often limited, and the process of labeling images can be labor-intensive and costly. This challenge significantly impedes the advancement and deployment of image classification models, especially in areas where rapid response is critical. The lack of scalability and the potential for reduced model performance due to a limited diversity in the labeled data impairs the model’s capacity to adapt to novel situations. Consequently, in environments where comprehensive datasets are scarce, strategically selecting a subset of unlabeled images for labeling becomes essential. This approach aims to construct a training set that is both efficient and effective, ensuring high accuracy in image classification tasks.
Active Learning represents a transformative approach in machine learning, focused on efficiently minimizing the burden and costs associated with labeling vast datasets. This technique strategically selects the most informative samples for labeling in each iteration, significantly reducing the size of the training set required to develop a high-performing model. This method is particularly beneficial in scenarios where data labeling is prohibitively expensive or labor-intensive. By employing Active Learning, we can not only develop robust image classification models under data-limited conditions but also adeptly adapt to dynamic data environments, such as those found in emerging social media platforms and high-resolution satellite imagery. The efficacy of Active Learning extends beyond image classification; it has been successfully implemented in diverse tasks, including image classification1,2,3, target detection4, and semantic segmentation5,6. This versatility underscores its immense potential for broader application across various domains within image classification and other areas of machine learning.
In the domain of Active Learning, various query strategies focus on selecting the most informative samples for current models. These strategies are typically divided into two categories: informativeness-based and representativeness-based. Informativeness-based methods prioritize unlabeled samples exhibiting the highest level of uncertainty, whereas representativeness-based methods emphasize sample diversity to mirror the underlying data distribution within the unlabeled data pool7,8. Despite their strengths, both approaches in Active Learning have faced criticism for over-focusing on data selection at the expense of considering the model’s capacity for comprehension. This oversight can lead to the selection of samples that exceed the model’s understanding, resulting in localized optimization and suboptimal performance. Furthermore, partitioning training data into excessive batches for training can markedly prolong the overall training duration. Consequently, there is a pressing need to devise more balanced and effective Active Learning methodologies. These should holistically encompass informativeness and representativeness, while also factoring in the model’s learning capabilities, to optimize both performance and efficiency in model training.
In response to the constraints inherent in conventional Active Learning strategies and driven by the necessity for efficient, adaptable, and high-performance image classification models, we introduce three innovative methods within the ambit of deep neural networks. These methods are conceptualized from a synthesis of existing literature, emphasizing the critical need to balance informativeness and representativeness in alignment with a model’s learning capacity.
Similarity-based Selection: This method evaluates the resemblance between unlabeled and labeled image datasets. It ensures that the selected unlabeled data accurately represent the already labeled dataset, mitigating the selection bias often encountered in uncertainty-based selection methods. This approach enhances the coverage of the data distribution space, ensuring a more comprehensive representation.
Prediction Probability-based Selection: Central to this method is the evaluation of the initial deep learning model’s classification performance on unlabeled datasets. It involves assessing the probability of each unlabeled data belonging to specific categories, thereby informing the subsequent training cycle. By anchoring the selection on the model’s current performance with the unlabeled data, we ensure that the newly integrated data is both informative and within the model’s learning capability.
Competence-based Active Learning: Drawing inspiration from human pedagogical techniques, which typically progress from simpler to more complex concepts, this method tailors the selection strategy to match the model’s learning progression and capacity. This is particularly crucial for deep learning models, which are susceptible to stagnation in local optima.
Our contributions are threefold: Firstly, we address the need for a balanced approach in Active Learning that aligns data selection with the model’s evolving learning capacity. Secondly, our proposed methods collectively facilitate a more effective and efficient training process, catering to the dynamic requirements of image classification tasks. Thirdly, Our experimental studies on the Cifar10 and Cifar100 datasets9 demonstrate that our innovative Active Learning methods surpass existing techniques in both efficacy and stability within the realm of image classification tasks. Key findings reveal that our approaches not only elevate the model’s generalization capacity but also significantly curtail the training duration compared to prior methodologies. By pioneering these novel solutions, our research aims to close prevailing gaps and catalyze progress in the field of image classification technology.
Related work
The field of Active Learning, particularly in image classification, has witnessed substantial advancements and diverse methodological approaches. This section provides an overview of these developments, categorizing them into key thematic areas and elucidating their respective contributions and limitations.
Active learning
Active Learning has proven to be effective in various applications, including image classification1,3,10,11, image retrieval12, image captioning13, object detection14, and regression15,16. In recent years, Active Learning strategies have been categorized into three main categories: informativeness16,17,18,19,20, representativeness8,10, and hybrid approaches21,22. Informativeness-based methods focus on selecting the most uncertain samples to clarify the areas of highest uncertainty in the model’s knowledge, thus promoting more robust learning. Representativeness-based methods aim to enhance the model’s generalization ability by exposing it to diverse training examples, ensuring the selected samples capture the full range of data variability. Hybrid approaches combine both informativeness and representativeness criteria to extract the most valuable information from the unlabeled data pool, thereby optimizing the efficiency and effectiveness of the learning process. Despite the success of these strategies, each method has its limitations. Informativeness-based methods, while focusing on selecting samples with the highest uncertainty, often overlook that not all diverse samples are equally beneficial for training. Representativeness-based methods enhance the model’s generalization ability by exposing it to diverse examples but might miss informative yet rare instances. Hybrid approaches, though aiming to balance these two criteria, often introduce increased complexity and computational costs. Our work aims to develop novel active learning strategies that address these limitations, maintaining high performance in image classification tasks.
classification tasks.
Informativeness-based method
Informativeness-based approaches are considered as the best strategy in Active Learning and they can be categorized into bayesian16 and non-bayesian23 frameworks. The bayesian approach, such as the one proposed by Gal et al.16, uses Monte Carlo Dropout to estimate the uncertainty of the unlabeled data. However, this method requires dense dropout layers, which can reduce the convergence speed and result in huge computational costs for large-scale learning. In contrast, non-Bayesian frameworks like the one proposed by Li et al.23 utilize an information density measure, defined as a metric to evaluate the significance of an unlabeled data sample by its proximity to other samples in the feature space, along with an uncertainty measure, to select pivotal instances for labeling. Non-Bayesian frameworks, using information density and uncertainty measures, select pivotal instances for labeling but may exhibit bias toward densely populated data regions, potentially overlooking valuable outliers. Recent work has attempted to overcome these limitations, for instance Ash et al.24 proposed a new method to measure data uncertainty by calculating the expected gradient length, while Li et al.25 rethought the structure of the loss prediction module and defined the acquisition function as a learning-to-rank problem. Yoo et al.7 and He et al.26 employ a loss module to learn the loss of a target model and select data based on their output loss. Despite these advancements, the challenge of balancing model uncertainty with computational efficiency and holistic data representation still persists. Overemphasis on uncertainty often leads to biases towards more challenging samples, leaving out simpler yet diverse instances that could improve the model’s overall generalization capability. Our methods, such as Prediction Probability-based Selection, are developed to address these biases by considering a balance between data density and informativeness, thus enhancing the Active Learning process.
Representativeness-based method
Representativeness-Based method usually uses a pre-trained self-supervised model to cluster the unlabeled data and select samples from each cluster that are most dissimilar to the already labeled samples. This method achieves good results in image classification tasks while reducing the number of labeled samples needed for training. In summary, representativeness-based methods focus on selecting diverse samples to enhance the robustness and generalization ability of the model. Sener et al.8 regard the step of selecting data as a issue of finding a current optimal set. In other words, a fixed number of samples are selected from the unlabeled data for the sake of adding to the set, and the newly added samples need to satisfy the maximum Euclidean distance from the samples in the set. The Core set method has been proved to be a relatively successful Active Learning algorithm. The Core-set method single out the samples by minimizing the Euclidian distance between the unlabeled data and labeled data in the feature space. However, the performance of this method is critically restricted by the data category in the datasets. To address this, Sinha et al.27 instead employ an adversarial approach to diversity-based sample query, which selects the unlabeled data based on the discriminator’s output, regards it as a selection criteria. However, the effectiveness and robustness of this approach can be influenced by the quality and reliability of the discriminator’s output. Furthermore, Bengar et al.28 integrated Active Learning with self-supervised pre-training, but further evaluation and analysis are required to assess its specific implementation and performance in different scenarios. While effective in enhancing the model’s robustness, they face limitations in accurately selecting the most informative and representative samples, impacting the efficiency of the sample selection process. These limitations include potential biases in diversity selection, the influence of discriminator output quality that refers to the effectiveness of a discriminator model, typically used in adversarial learning, in distinguishing between different categories or classes of data. Therefore, there is a need for further advancements and novel approaches to address these limitations and improve the overall sample selection process in Active Learning. Our Competence-based Active Learning method addresses the limitations of these representativeness-based methods by integrating the model’s learning capacity with the selection process, thus ensuring a more effective and balanced Active Learning approach.
Curriculum learning
The concept of Curriculum Learning draws inspiration from the learning process observed in humans and animals, where they gradually take on more challenging tasks once they have mastered easier ones. This approach has been a topic of interest for many years29. In traditional machine learning, models often randomly select small batches of data from the training set and update the model parameters using stochastic gradient descent. In machine learning models, this approach can prevent models, especially deep learning models, from getting trapped in local optima, leading to better generalization performance. However, the random selection of data in traditional models can result in prolonged training times and subpar performance.
In response to the insights from the study in reference30, we have innovated a novel method for data selection in the realm of image classification. This technique focuses on evaluating the complexity of unlabeled images relative to the model’s current learning trajectory, using the model’s own probability estimates for its predictions as a basis. Our methodology is an intersection of Curriculum Learning principles and Active Learning techniques, crafted to progressively introduce more challenging samples to the model, thereby fostering a more robust learning process. We have refined this approach with the incorporation of a competence-based strategy, which calibrates the complexity of training samples to the model’s evolving learning stage. Rigorous experimentation has established that our method not only significantly reduces the number of training iterations required but also markedly enhances the model’s generalization capabilities.
Method
Our image classification framework is based on Active Learning, which involves a large pool of unlabeled data \(D_{U}\) and a labeled dataset \(D_{L}\). In each cycle, we select N samples for annotation to maximize our classification model’s performance. Active Learning methods typically allocate the budget sequentially over a few cycles, with the batch-mode variant labeling b samples per cycle as the only viable option for CNN31 training. At the start of each cycle, we train the model on the labeled set \(D_{L}\) and then use our proposed acquisition function to select a certain amount of data from \(D_{U}\) to add to \(D_{L}\). We then retrain the model using the updated dataset and repeat this process until all selected samples are trained. The acquisition function is the most crucial component and the main point of difference among Active Learning methods in the literature. Figure 1 provides an overview of our Active learning framework, our objective is to identify the most valuable images from unlabeled datasets, which can enhance the model’s performance. To achieve this goal, we have developed methods for selecting informative images for image classification within an Active Learning framework.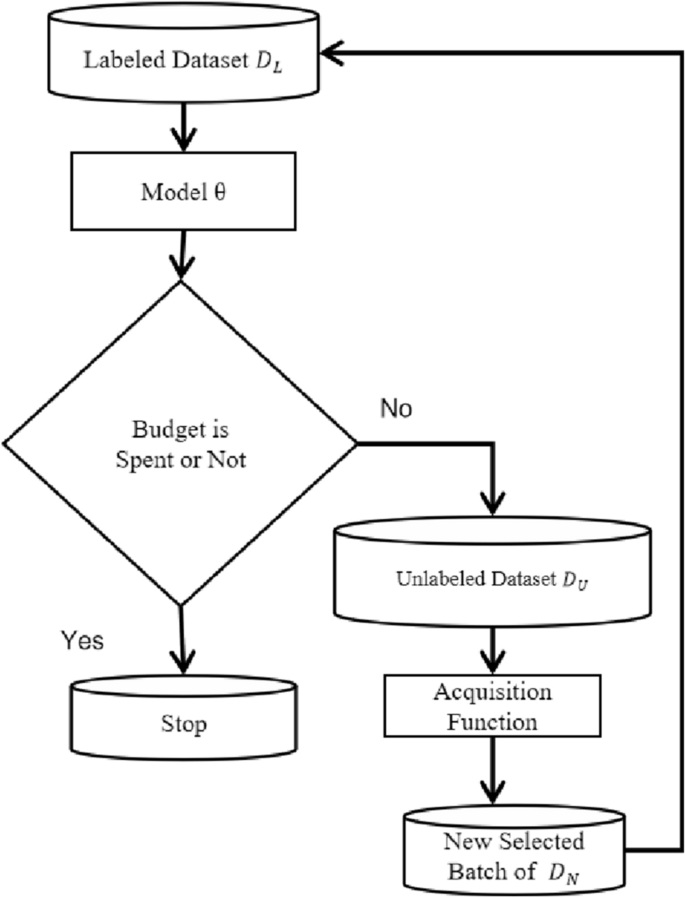
In our research, we have developed two distinct data selection methodologies: Similarity-based Selection, dedicated exclusively to data selection, and Prediction Probability-Based Selection, which is integrated with our novel Competence-based Active Learning framework for model training. Our approach to data selection is twofold: one aspect focuses on the inherent characteristics of the data, while the other considers the requirements of the model in use. From the data’s standpoint, we prioritize the diversity and richness of information encapsulated in the images during our selection process. In terms of model considerations, we strategically select data that provides the most value to the model’s current stage of learning. Specifically, in the domain of image classification, our selection criterion hinges on assessing the difficulty level of classifying each image, tailored to the model’s current capabilities.
Similarity-based selection
We use image embeddings to calculate the similarity between images and exclude images that are similar to those already selected. Image embedding is a low-dimensional continuous image space representation. To estimate the score of an image, we follow these steps:
The score of an image s is determined using its embedding, represented by emb(s). To compute this score, we first calculate the similarity between image s and all the images in the labeled datasets. The largest value of this similarity is selected as the similarity of image s to the labeled datasets. A higher 𝑆𝑠𝑐𝑜𝑟𝑒(𝑠) indicates that image s is more dissimilar to the labeled datasets. We select image s to be included in 𝐷𝐿, if it has significant image information and is not redundant with high probability. We believe that these dissimilar images are more valuable to the current model than other similar images, considering the image information. At each iteration, we select the top N images based on their 𝑆𝑠𝑐𝑜𝑟𝑒(𝑠) and add them to 𝐷𝐿 while removing them from 𝐷𝑈. The Fig. 2 shows the algorithm.

