Abstract
Large Language Models (LLMs) have recently demonstrated remarkable capabilities in natural language processing tasks and beyond. This success of LLMs has led to a large influx of research contributions in this direction. These works encompass diverse topics such as architectural innovations, better training strategies, context length improvements, fine-tuning, multi-modal LLMs, robotics, datasets, benchmarking, efficiency, and more. With the rapid development of techniques and regular breakthroughs in LLM research, it has become considerably challenging to perceive the bigger picture of the advances in this direction. Considering the rapidly emerging plethora of literature on LLMs, it is imperative that the research community is able to benefit from a concise yet comprehensive overview of the recent developments in this field. This article provides an overview of the existing literature on a broad range of LLM-related concepts. Our self-contained comprehensive overview of LLMs discusses relevant background concepts along with covering the advanced topics at the frontier of research in LLMs. This review article is intended to not only provide a systematic survey but also a quick comprehensive reference for the researchers and practitioners to draw insights from extensive informative summaries of the existing works to advance the LLM research.
Index Terms:
Large Language Models, LLMs, chatGPT, Augmented LLMs, Multimodal LLMs, LLM training, LLM Benchmarking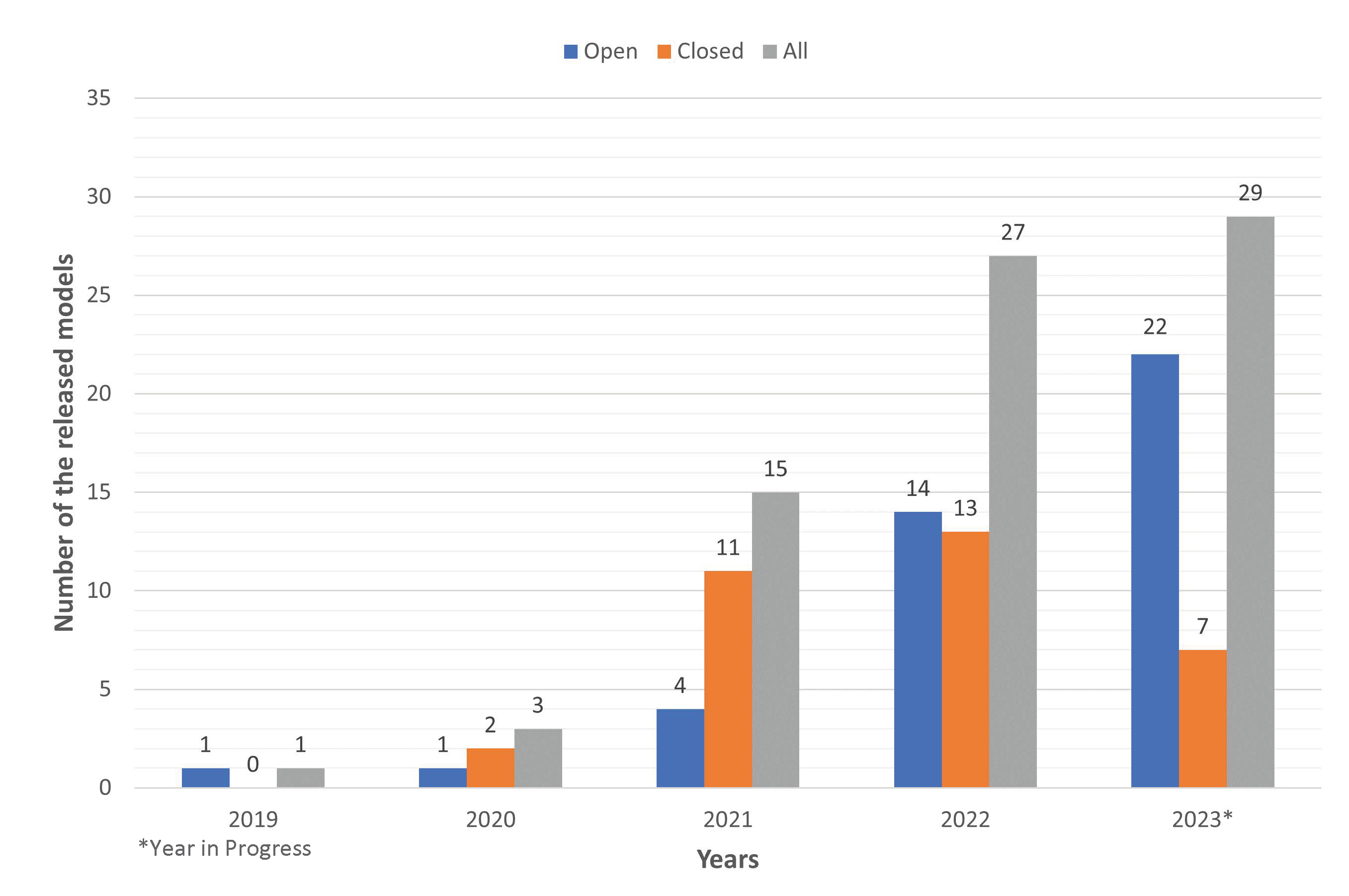
IIntroduction
Language plays a fundamental role in facilitating communication and self-expression for humans, and their interaction with machines. The need for generalized models stems from the growing demand for machines to handle complex language tasks, including translation, summarization, information retrieval, conversational interactions, etc. Recently, significant breakthroughs have been witnessed in language models, primarily attributed to transformers [1], increased computational capabilities, and the availability of large-scale training data. These developments have brought about a revolutionary transformation by enabling the creation of LLMs that can approximate human-level performance on various tasks [2, 3]. Large Language Models (LLMs) have emerged as cutting-edge artificial intelligence systems that can process and generate text with coherent communication [4], and generalize to multiple tasks [5, 6].
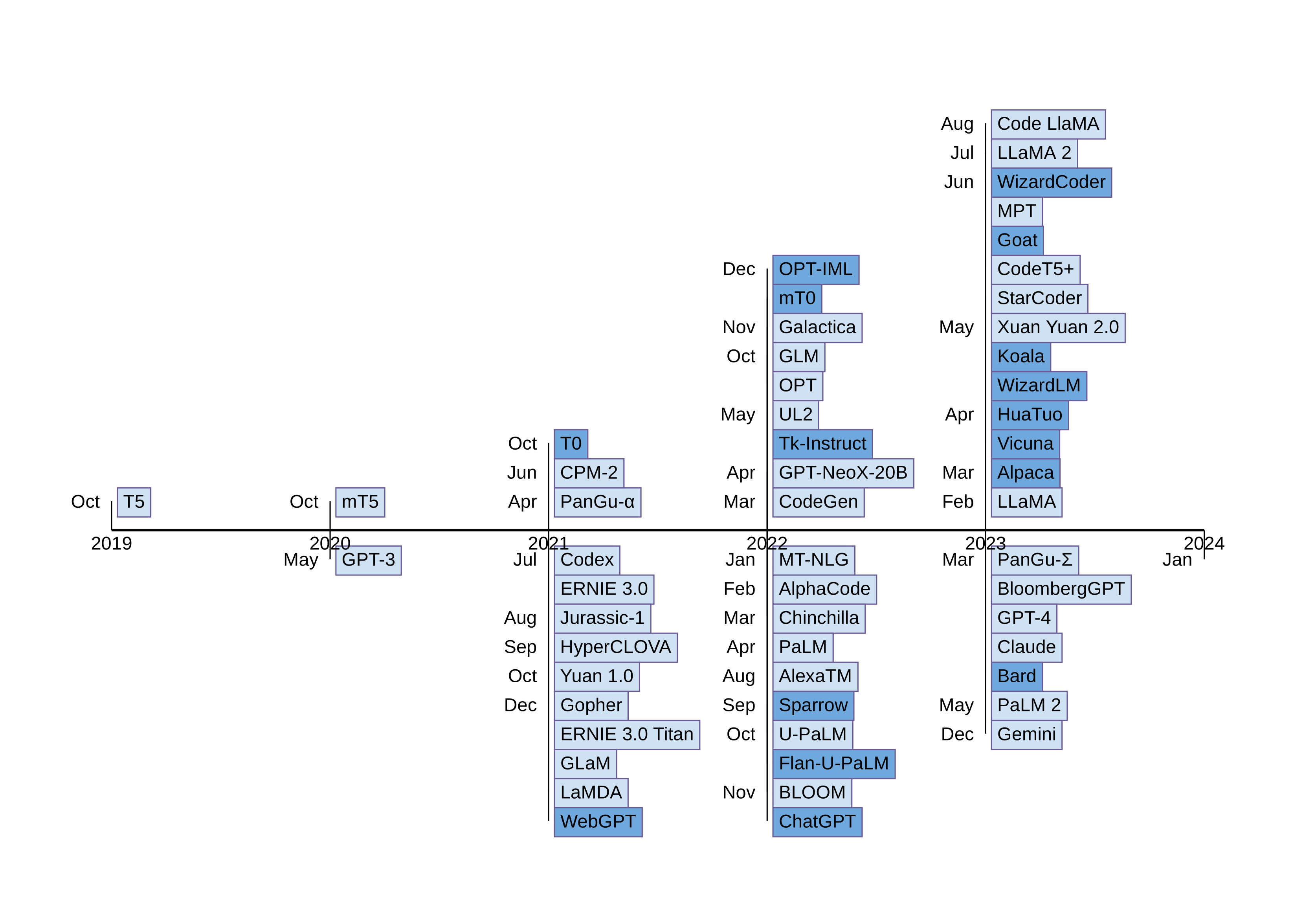
The historical progress in natural language processing (NLP) evolved from statistical to neural language modeling and then from pre-trained language models (PLMs) to LLMs. While conventional language modeling (LM) trains task-specific models in supervised settings, PLMs are trained in a self-supervised setting on a large corpus of text [7, 8, 9] with the aim to learn generic representation shareable among various NLP tasks. After fine-tuning for downstream tasks, PLMs surpass the performance gains of traditional language modeling (LM). The larger PLMs bring more performance gains, which has led to the transitioning of PLMs to LLMs by significantly increasing model parameters (tens to hundreds of billions) [10] and training dataset (many GBs and TBs) [10, 11]. Following this development, numerous LLMs have been proposed in the literature [10, 11, 12, 6, 13, 14, 15]. An increasing trend in the number of released LLMs and names of a few significant LLMs proposed over the years are shown in Fig 1 and Fig 2, respectively.
The early work on LLMs, such as T5 [10] and mT5 [11] employed transfer learning until GPT-3 [6] showing LLMs are zero-shot transferable to downstream tasks without fine-tuning. LLMs accurately respond to task queries when prompted with task descriptions and examples. However, pre-trained LLMs fail to follow user intent and perform worse in zero-shot settings than in few-shot. Fine-tuning them with task instructions data [16, 17, 18, 19] and aligning with human preferences [20, 21] enhances generalization to unseen tasks, improving zero-shot performance significantly and reducing misaligned behavior.
Additional to better generalization and domain adaptation, LLMs appear to have emergent abilities, such as reasoning, planning, decision-making, in-context learning, answering in zero-shot settings, etc. These abilities are known to be acquired by them due to their gigantic scale even when the pre-trained LLMs are not trained specifically to possess these attributes [22, 23, 24]. Such abilities have led LLMs widely adopted in diverse settings including, multi-modal, robotics, tool manipulation, question answering, autonomous agents, etc. Various improvements have also been suggested in these areas either by task-specific training [25, 26, 27, 28, 29, 30, 31] or better prompting [32].
The LLMs abilities to solve diverse tasks with human-level performance come at a cost of slow training and inference, extensive hardware requirements, and higher running costs. Such requirements have limited their adoption and opened up opportunities to devise better architectures [15, 33, 34, 35] and training strategies [36, 37, 21, 38, 39, 40, 41]. Parameter efficient tuning [38, 41, 40], pruning, quantization, knowledge distillation, and context length interpolation [42, 43, 44, 45] among others are some of the methods widely studied for efficient LLM utilization.
Due to the success of LLMs on a wide variety of tasks, the research literature has recently experienced a large influx of LLM-related contributions. Researchers have organized the LLMs literature in surveys [46, 47, 48, 49], and topic-specific surveys in [50, 51, 52, 53, 54]. In contrast to these surveys, our contribution focuses on providing a comprehensive yet concise overview of the general direction of LLM research. This article summarizes architectural and training details of pre-trained LLMs and delves deeper into the details of concepts like fine-tuning, multi-modal LLMs, robotics, augmented LLMs, datasets, evaluation, and others to provide a self-contained comprehensive overview. Our key contributions are summarized as follows.
- •
We present a survey on the developments in LLM research with the specific aim of providing a concise yet comprehensive overview of the direction.
- •
We present extensive summaries of pre-trained models that include fine-grained details of architecture and training details.
- •
Besides paying special attention to the chronological order of LLMs throughout the article, we also summarize major findings of the popular contributions and provide detailed discussion on the key design and development aspects of LLMs to help practitioners to effectively leverage this technology.
- •
In this self-contained article, we cover a range of concepts to comprehend the general direction of LLMs comprehensively, including background, pre-training, fine-tuning, robotics, multi-modal LLMs, augmented LLMs, datasets, evaluation, etc.
We loosely follow the existing terminologies to ensure providing a more standardized outlook of this research direction. For instance, following [46], our survey discusses pre-trained LLMs with 10B parameters or more. We refer the readers interested in smaller pre-trained models to [47, 48, 49].
The organization of this paper is as follows. Section II discusses the background of LLMs. Section III focuses on LLMs overview, architectures, training pipelines and strategies, and utilization in different aspects. Section IV presents the key findings derived from each LLM. Section V highlights the configuration and parameters that play a crucial role in the functioning of these models. Summary and discussions are presented in section VIII. The LLM training and evaluation, datasets and benchmarks are discussed in section VI, followed by challenges and future directions and conclusion in sections IX and X, respectively.
IIBackground
We provide the relevant background to understand the fundamentals related to LLMs in this section. Aligned with our objective of providing a comprehensive overview of this direction, this section offers a comprehensive yet concise outline of the basic concepts. We focus more on the intuitive aspects and refer the readers interested in details to the original works.
II-ATokenization
LLMs are trained on text to predict text, and similar to other natural language processing systems, they use tokenization [55] as the essential preprocessing step. It aims to parse the text into non-decomposing units called tokens. Tokens can be characters, subwords [56], symbols [57], or words, depending on the size and type of the model. Some of the commonly used tokenization schemes in LLMs are briefed here. Readers are encouraged to refer to [58] for a detailed survey.
II-A1WordPiece [59]
It was introduced in [59] as a novel text segmentation technique for Japanese and Korean languages to improve the language model for voice search systems. WordPiece selects tokens that increase the likelihood of an n-gram-based language model trained on the vocabulary composed of tokens.
II-A2BPE [57]
Byte Pair Encoding (BPE) has its origin in compression algorithms. It is an iterative process of generating tokens where pairs of adjacent symbols are replaced by a new symbol, and the occurrences of the most occurring symbols in the input text are merged.
II-A3UnigramLM [56]
In this tokenization, a simple unigram language model (LM) is trained using an initial vocabulary of subword units. The vocabulary is pruned iteratively by removing the lowest probability items from the list, which are the worst performing on the unigram LM.
II-BAttention
Attention, particularly selective attention, has been widely studied under perception, psychophysics, and psychology. Selective attention can be conceived as “the programming by the O of which stimuli will be processed or encoded and in what order this will occur” [60]. While this definition has its roots in visual perception, it has uncanny similarities with the recently formulated attention [61, 62] (which stimuli will be processed) and positional encoding (in what order this will occur) [62] in LLMs. We discuss both in sections II-C and II-D, respectively.
II-CAttention in LLMs
The attention mechanism computes a representation of the input sequences by relating different positions (tokens) of these sequences. There are various approaches to calculating and implementing attention, out of which some famous types are given below.
II-C1Self-Attention [62]
The self-attention is also known as intra-attention since all the queries, keys, and values come from the same block (encoder or decoder). The self-attention layer connects all the sequence positions with 𝑂(1) space complexity which is highly desirable for learning long-range dependencies in the input.
II-C2Cross Attention
In encoder-decoder architectures, the outputs of the encoder blocks act as the queries to the intermediate representation of the decoder, which provides the keys and values to calculate a representation of the decoder conditioned on the encoder. This attention is called cross-attention.
II-C3Full Attention
The naive implementation of calculating self-attention is known as full attention.
II-C4Sparse Attention [63]
The self-attention has a time complexity of 𝑂(𝑛2), which becomes prohibitive when scaling the LLMs to large context windows. An approximation to the self-attention was proposed in [63], which greatly enhanced the capacity of GPT series LLMs to process a greater number of input tokens in a reasonable time.
II-C5Flash Attention [64]
The bottleneck for calculating the attention using GPUs lies in the memory access rather than the computational speed. Flash Attention uses the classical input tiling approach to process the blocks of the input in GPU on-chip SRAM rather than doing IO for every token from the High Bandwith Memory (HBM). An extension of this approach to sparse attention follows the speed gains of the full attention implementation. This trick allows even greater context-length windows in the LLMs as compared to those LLMs with sparse attention.
II-DEncoding Positions
The attention modules do not consider the order of processing by design. Transformer [62] introduced “positional encodings” to feed information about the position of the tokens in input sequences. Several variants of positional encoding have been proposed [65, 66]. Interestingly, a recent study [67] suggests that adding this information may not matter for the state-of-the-art decoder-only Transformers.
II-D1Absolute
This is the most straightforward approach to adding the sequence order information by assigning a unique identifier to each position of the sequence before passing it to the attention module.
II-D2Relative
To pass the information on the relative dependencies of different tokens appearing at different locations in the sequence, a relative positional encoding is calculated by some kind of learning. Two famous types of relative encodings are:
Alibi: [65] In this approach, a scalar bias is subtracted from the attention score calculated using two tokens which increases with the distance between the positions of the tokens. This learned approach effectively favors using recent tokens for attention.
RoPE: Keys, queries, and values are all vectors in the LLMs. RoPE [66] involves the rotation of the query and key representations at an angle proportional to their absolute positions of the tokens in the input sequence. This step results in a relative positional encoding scheme which decays with the distance between the tokens.
II-EActivation Functions
The activation functions serve a crucial role in the curve-fitting abilities of the neural networks, as proved in [68]. The modern activation functions used in LLMs are different from the earlier squashing functions but are critical to the success of LLMs. We discuss these activation functions in this section.
II-E1ReLU [69]
Rectified linear unit (ReLU) is defined as
| 𝑅𝑒𝐿𝑈(𝑥)=𝑚𝑎𝑥(0,𝑥) | (1) |
II-E2GeLU [70]
II-E3GLU variants [73]
Gated Linear Unit [74] is a neural network layer that is an element-wise product (⊗) of a linear transformation and a sigmoid transformed (𝜎) linear projection of the input given as
| 𝐺𝐿𝑈(𝑥,𝑊,𝑉,𝑏,𝑐)=(𝑥𝑊+𝑏)⊗𝜎(𝑥𝑉+𝑐), | (2) |
where 𝑋 is the input of layer and 𝑙, 𝑊,𝑏,𝑉 and 𝑐 are learned parameters.
GLU was modified in [73] to evaluate the effect of different variations in the training and testing of transformers, resulting in better empirical results. Here are the different GLU variations introduced in [73] and used in LLMs.
| 𝑅𝑒𝐺𝐿𝑈(𝑥,𝑊,𝑉,𝑏,𝑐) | =𝑚𝑎𝑥(0,𝑥𝑊+𝑏)⊗, | ||
| 𝐺𝐸𝐺𝐿𝑈(𝑥,𝑊,𝑉,𝑏,𝑐) | =𝐺𝐸𝐿𝑈(𝑥𝑊+𝑏)⊗(𝑥𝑉+𝑐), | ||
| 𝑆𝑤𝑖𝐺𝐿𝑈(𝑥,𝑊,𝑉,𝑏,𝑐,𝛽) | =𝑆𝑤𝑖𝑠ℎ𝛽(𝑥𝑊+𝑏)⊗(𝑥𝑉+𝑐). |
II-FLayer Normalization
Layer normalization leads to faster convergence and is a widely used component in transformers. In this section, we provide different normalization techniques widely used in LLM literature.
II-F1LayerNorm
Layer norm computes statistics over all the hidden units in a layer (𝑙) as follows:
| 𝑢𝑙=1𝑛∑𝑖𝑛𝑎𝑖𝑙𝜎𝑙=1𝑛∑𝑖𝑛(𝑎𝑖𝑙−𝑢𝑙)2, | (3) |
where 𝑛 is the number of neurons in the layer 𝑙 and 𝑎𝑖𝑙 is the summed input of the 𝑖 neuron in layer 𝑙. LayerNorm provides invariance to rescaling of the weights and re-centering of the distribution.
II-F2RMSNorm
[75] proposed that the invariance properties of LayerNorm are spurious, and we can achieve the same performance benefits as we get from LayerNorm by using a computationally efficient normalization technique that trades off re-centering invariance with speed. LayerNorm gives the normalized summed input to layer 𝑙 as follows
| 𝑎𝑖𝑙¯=𝑎𝑖𝑙−𝑢𝑙𝜎𝑔𝑖𝑙 | (4) |
where 𝑔𝑖𝑙 is the gain parameter. RMSNorm [75] modifies 𝑎𝑖𝑙¯ as
| 𝑎𝑖𝑙¯=𝑎𝑖𝑙RMS(𝐚𝑙)𝑔𝑖𝑙,whereRMS(𝐚𝑙)=1𝑛∑𝑖𝑛(𝑎𝑖𝑙)2. | (5) |
II-F3Pre-Norm and Post-Norm
LLMs use transformer [62] architecture with some variations. The original implementation [62] used layer normalization after the residual connection, commonly called post-LN, concerning the order of Multihead attention – Residual – LN. There is another order of the normalization, referred to as pre-LN [76] due to the position of the normalization step before the self-attention layer as in LN – Multihead attention – Residual. Pre-LN is known to provide more stability in the training [77].
II-F4DeepNorm
While pre-LN has certain benefits over post-LN training, pre-LN training has an unwanted effect on the gradients [77]. The earlier layers have larger gradients than those at the bottom. DeepNorm [78] mitigates these adverse effects on the gradients. It is given as
| 𝐱𝑙𝑓=𝐿𝑁(𝛼𝐱𝑙𝑝+𝐺𝑙𝑝(𝐱𝑙𝑝,𝜃)𝑙𝑝, | (6) |
where 𝛼 is a constant and 𝜃𝑙𝑝 represents the parameters of layer 𝑙𝑝. These parameters are scaled by another constant 𝛽. Both of these constants depend only on the architecture.
II-GDistributed LLM Training
This section describes distributed LLM training approaches briefly. More details are available in [13, 37, 79, 80].
II-G1Data Parallelism
Data parallelism replicates the model on multiple devices where data in a batch gets divided across devices. At the end of each training iteration weights are synchronized across all devices.
II-G2Tensor Parallelism
Tensor parallelism shards a tensor computation across devices. It is also known as horizontal parallelism or intra-layer model parallelism.
II-G3Pipeline Parallelism
Pipeline parallelism shards model layers across different devices. This is also known as vertical parallelism.
II-G4Model Parallelism
A combination of tensor and pipeline parallelism is known as model parallelism.
II-G53D Parallelism
A combination of data, tensor, and model parallelism is known as 3D parallelism.
II-G6Optimizer Parallelism
Optimizer parallelism also known as zero redundancy optimizer [37] implements optimizer state partitioning, gradient partitioning, and parameter partitioning across devices to reduce memory consumption while keeping the communication costs as low as possible.
II-HLibraries
II-IData PreProcessing
This section briefly summarizes data preprocessing techniques used in LLMs training.
II-I1Quality Filtering
For better results, training data quality is essential. Some approaches to filtering data are: 1) classifier-based and 2) heuristics-based. Classifier-based approaches train a classifier on high-quality data and predict the quality of text for filtering, whereas heuristics-based employ some rules for filtering like language, metrics, statistics, and keywords.
II-I2Data Deduplication
Duplicated data can affect model performance and increase data memorization; therefore, to train LLMs, data deduplication is one of the preprocessing steps. This can be performed at multiple levels, like sentences, documents, and datasets.
II-I3Privacy Reduction
Most of the training data for LLMs is collected through web sources. This data contains private information; therefore, many LLMs employ heuristics-based methods to filter information such as names, addresses, and phone numbers to avoid learning personal information.
II-JArchitectures
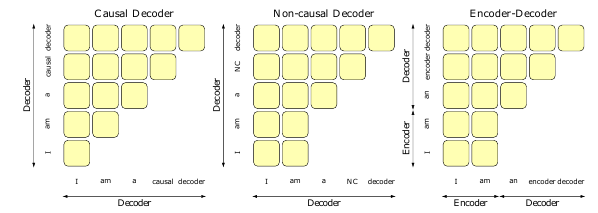
Here we discuss the variants of the transformer architectures at a higher level which arise due to the difference in the application of the attention and the connection of transformer blocks. An illustration of attention patterns of these architectures is shown in Figure 4.
II-J1Encoder Decoder
Transformers were originally designed as sequence transduction models and followed other prevalent model architectures for machine translation systems. They selected encoder-decoder architecture to train human language translation tasks. This architecture is adopted by [10, 89]. In this architectural scheme, an encoder encodes the input sequences to variable length context vectors, which are then passed to the decoder to maximize a joint objective of minimizing the gap between predicted token labels and the actual target token labels.
II-J2Causal Decoder
The underlying objective of an LLM is to predict the next token based on the input sequence. While additional information from the encoder binds the prediction strongly to the context, it is found in practice that the LLMs can perform well in the absence of encoder [90], relying only on the decoder. Similar to the original encoder-decoder architecture’s decoder block, this decoder restricts the flow of information backward, i.e., the predicted token 𝑡𝑘 only depends on the tokens preceded by and up to 𝑡𝑘−1. This is the most widely used variant in the state-of-the-art LLMs.
II-J3Prefix Decoder
The causal masked attention is reasonable in the encoder-decoder architectures where the encoder can attend to all the tokens in the sentence from every position using self-attention. This means that the encoder can also attend to tokens 𝑡𝑘+1 to 𝑡𝑛 in addition to the tokens from 𝑡1 to 𝑡𝑘−1 while calculating the representation for 𝑡𝑘. But when we drop the encoder and only keep the decoder, we also lose this flexibility in attention. A variation in the decoder-only architectures is by changing the mask from strictly causal to fully visible on a portion of the input sequence, as shown in Figure 4. The Prefix decoder is also known as non-causal decoder architecture.